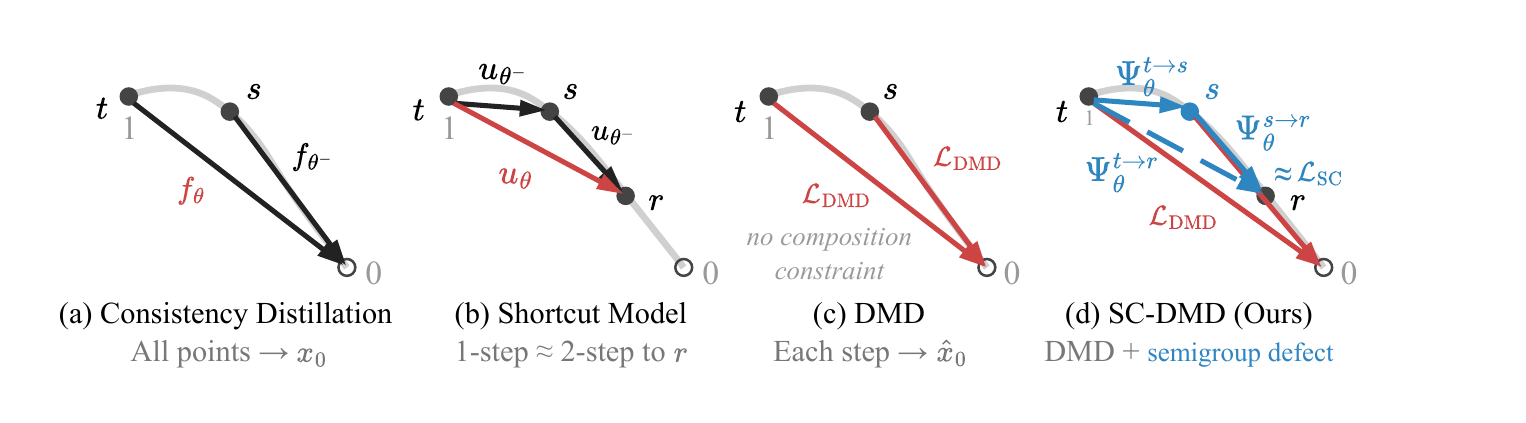
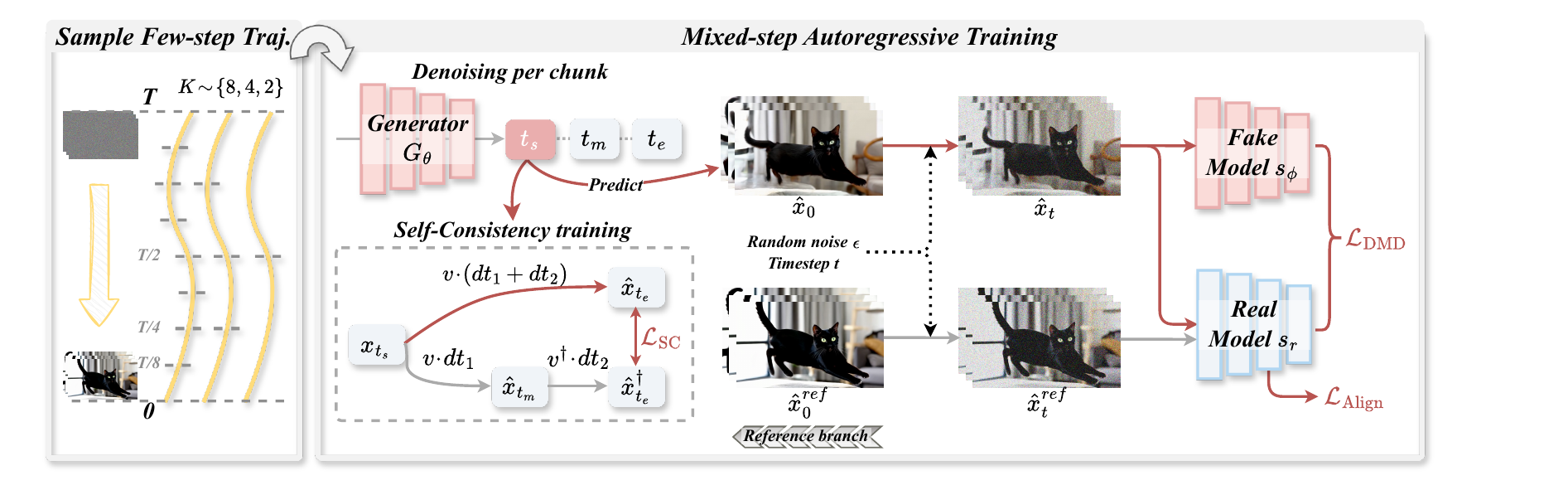
Distilling video generation models to extremely low inference budgets is crucial for real-time deployment, yet remains difficult. Trajectory-style consistency distillation can become conservative under complex video dynamics, while Distribution Matching Distillation (DMD) produces sharper samples but lacks an explicit constraint on how denoising updates compose across timesteps. Salt addresses this gap with Self-Consistent Distribution Matching Distillation (SC-DMD), which regularizes the endpoint-consistent composition of consecutive denoising updates. For real-time autoregressive video generation, Salt further treats the KV cache as a quality-parameterized condition and introduces Cache-Distribution-Aware training with multi-step rollouts and cache-conditioned feature alignment. Across non-autoregressive and autoregressive backbones, Salt improves low-NFE video generation while adding no inference overhead.

Salt improves few-step video generation quality and temporal stability for both non-autoregressive and autoregressive settings.